Quand WordPress devient un serveur d’outils, pas juste un CMS
1. Le vrai problème des contenus internes aujourd’hui
Soyons clairs :
dans beaucoup d’entreprises, l’information existe… mais elle est inexploitable.
Elle est rarement absente.
En revanche, elle est éparpillée, mal structurée, et surtout difficile à interroger intelligemment.

On retrouve généralement :
- des pages WordPress internes, parfois anciennes ou mal classées,
- des PDF stockés dans la médiathèque,
- des notes internes jamais consolidées,
- des procédures écrites “quelque part”, sans logique de recherche globale.
Dès qu’une question transversale apparaît :
On avait fait quoi la dernière fois sur ce client ?
Où est la procédure pour ce cas précis ?
Est-ce qu’on a déjà traité ce sujet ?
La réponse est presque toujours la même :
recherche manuelle, scroll, ouverture de multiples onglets… puis abandon ou approximation.
Le problème n’est pas le volume de contenu.
Le problème, c’est l’absence d’un accès structuré et intelligent à ce contenu.
2. Pourquoi la recherche WordPress classique ne suffit pas
(et pourquoi ce n’est pas un défaut)
Il faut poser une base saine :
WordPress n’a jamais été conçu comme un moteur de recherche documentaire interne.
À l’origine, WordPress est un CMS orienté vers l’extérieur.
Il est pensé pour :
- publier du contenu,
- le rendre consultable publiquement,
- organiser l’information pour des visiteurs.
Dans ce cadre-là, ses mécanismes sont cohérents et éprouvés.
Ce que WordPress propose nativement
WordPress repose sur deux mécanismes fondamentaux.
La recherche par mots-clés (?s=) effectue une recherche textuelle simple dans les titres et contenus.
Elle est rapide, peu coûteuse, mais reste purement lexicale.
La classification par taxonomies (catégories, tags, taxonomies personnalisées) permet de structurer l’information.
C’est un excellent système de rangement, mais pas un moteur de compréhension.
Ces mécanismes sont parfaitement adaptés à un site web classique.
Ils ne sont simplement pas conçus pour répondre à des questions métiers formulées en langage naturel.
Les plugins de recherche avancée et l’indexation à facettes
Il existe bien entendu des solutions plus poussées :
- moteurs de recherche à facettes,
- indexation avancée,
- filtres multi-critères,
- pondération des champs,
- recherche dans les métadonnées (ACF, CPT, etc.).
Ces outils reposent sur une logique d’indexation à facettes.
Le principe est connu :
on découpe l’information en critères,
on expose ces critères sous forme de filtres,
et l’utilisateur affine progressivement les résultats.
Techniquement, c’est solide.
Fonctionnellement, cela suppose que l’utilisateur :
- connaisse la structure des données,
- sache quels filtres activer,
- raisonne en critères plutôt qu’en intention.
Ces systèmes sont puissants, mais ils restent orientés “recherche”, pas “compréhension”.
Ils ne sont pas conversationnels.
Le décalage clé : intention vs mots-clés
Prenons un exemple concret :
Comment on gère un devis non signé dans WooCommerce ?
Une recherche WordPress classique va extraire les mots-clés :
- devis,
- WooCommerce,
- signé.
Mais elle ne comprend pas que :
- la demande porte sur une procédure interne,
- liée à un cas métier précis,
- probablement déjà documenté,
- potentiellement réparti sur plusieurs contenus (article, note interne, retour d’expérience).
Le résultat est alors prévisible :
- soit trop de résultats,
- soit aucun,
- soit un contenu partiellement pertinent.
Ce n’est pas une faiblesse de WordPress.
C’est simplement en dehors de son périmètre fonctionnel d’origine.
3. Là où WordPress devient réellement intéressant avec un MCP
C’est précisément à ce moment-là que le MCP change la donne.
WordPress dispose d’un avantage structurel majeur :
un modèle de données simple, extensible et extrêmement bien maîtrisé.

Il permet nativement :
- de gérer des contenus structurés (posts, pages),
- de créer des types de contenus personnalisés (CPT),
- d’enrichir ces contenus via des champs méta ou ACF,
- de proposer une interface d’édition connue des équipes,
- d’évoluer sans refonte lourde du système.
C’est cette combinaison qui explique son adoption massive, y compris en entreprise.
WordPress propulse aujourd’hui plus de 40 % du web.
Stocker la documentation dans un environnement maîtrisé
L’objectif n’est pas de transformer WordPress en moteur d’IA.
L’objectif est plus pragmatique :
utiliser WordPress comme socle documentaire structuré, puis fournir à une IA des outils pour exploiter cette base.
La notion de documentation est volontairement large :
- procédures internes,
- listes de contacts selon des situations données,
- notices techniques (de la plus simple à la plus complexe),
- procédures de maintenance ou de remplacement de pièces,
- checklists,
- historiques de décisions,
- retours d’expérience,
- documents RH ou techniques.
Ce type d’approche devient pertinent dès que :
- l’entreprise grandit,
- l’information circule moins naturellement,
- la mémoire collective commence à se fragmenter.
4. WordPress comme serveur MCP : qui fait quoi
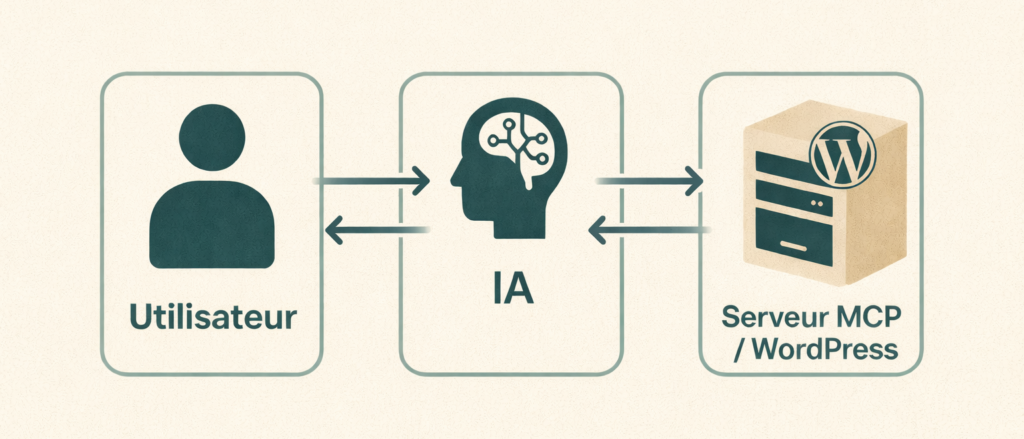
l’IA agit comme un client et intermédiaire avec l’utilisateur
Il est important d’être précis sur l’architecture.
Dans ce modèle :
- WordPress héberge le serveur MCP
- L’IA est cliente du serveur MCP
Le flux réel est donc :
Utilisateur → IA → MCP / WordPress
L’utilisateur ne parle pas à WordPress.
Il parle à une IA, qui agit comme cliente d’un serveur MCP hébergé par WordPress.
5. Une alternative pragmatique aux bases de données vectorielles
Aujourd’hui, dans beaucoup d’architectures IA, la place occupée ici par WordPress est tenue par :
- des bases de données vectorielles,
- des services SaaS spécialisés,
- des infrastructures coûteuses et complexes.
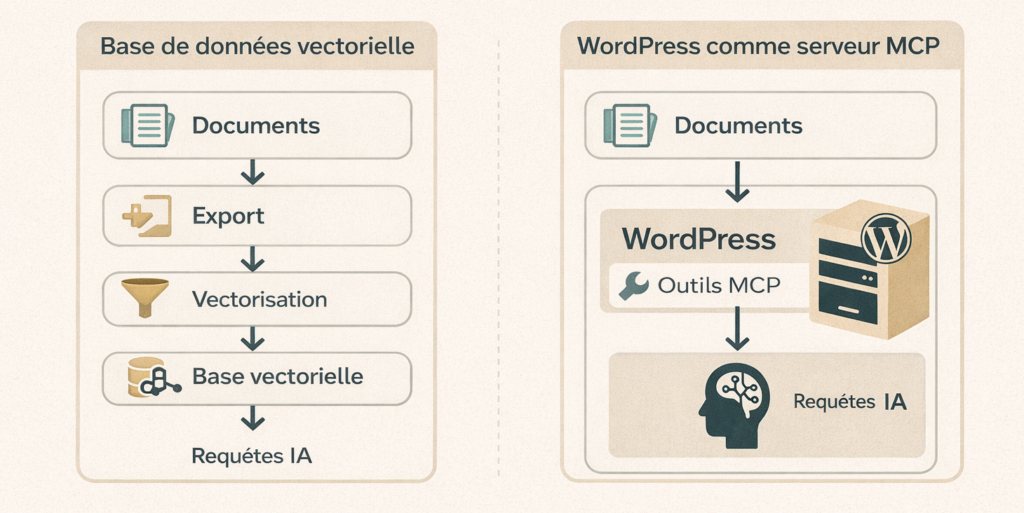
Ces solutions impliquent :
- l’export des documents,
- leur vectorisation,
- un stockage externe,
- un pipeline de synchronisation,
- des coûts récurrents non négligeables.
Avec un MCP hébergé dans WordPress, la logique est inversée :
- les données restent là où elles sont déjà,
- WordPress expose des outils d’accès intelligents,
- l’IA vient interroger ces outils comme n’importe quel client MCP.
Dans un périmètre raisonnable — quelques dizaines à quelques centaines de documents —
un WordPress bien structuré, hébergé sur un serveur correctement dimensionné, peut tenir la dragée haute à une solution vectorielle classique.
Pour des archives très volumineuses (plusieurs années, milliers de documents), la question devient :
- puissance serveur,
- optimisation des requêtes,
- stratégie d’outils MCP,
- et modèle d’IA utilisé.
Ce n’est pas une limite conceptuelle, mais une question d’architecture.
6. L’IA n’accède jamais aux données directement
C’est un point fondamental.
👉 L’IA n’a aucun accès direct à WordPress.
👉 Elle ne peut appeler que les outils exposés par le serveur MCP.
Exemples d’outils exposés :
- list_tags
- list_categories
- search_by_tag
- search_by_category
- search_by_keywords
- fetch_post_by_id
L’IA orchestre ces outils :
- elle explore,
- recoupe,
- lit,
- synthétise.
Elle agit comme un agent documentaire, pas comme un crawler libre.
7. Contrôle d’accès : ce n’est pas l’IA qui décide
Autre point essentiel :
le contrôle d’accès ne repose pas sur le prompt.
Le serveur MCP est le point d’autorité.
Il peut être configuré pour :
- limiter l’accès à certains types de contenus,
- exclure des catégories sensibles (ex. RH),
- adapter le périmètre de recherche selon le contexte ou l’utilisateur.
Techniquement, cela se traduit par des WP_Query différentes, définies côté serveur MCP.
Exemple :
- un utilisateur standard n’interroge jamais les documents RH,
- même si le prompt tente de les cibler.
Ce n’est pas une décision de l’IA.
C’est une contrainte technique.
👉 Aucun contournement possible par le prompt.
👉 Si un contenu n’est pas inclus dans la requête WordPress, il n’existe pas pour l’IA.
La sécurité est structurelle, pas déclarative.
8. Une architecture fermée et maîtrisée
Dans cette approche, le WordPress documentaire peut être :
- totalement fermé à Internet,
- sans front public,
- sans REST API exposée.
L’accès est limité :
- à l’IP de l’IA,
- à l’IP de l’administrateur,
- au serveur MCP.
WordPress devient une brique backend, pas un site web.
9. Une mémoire de contexte persistante
Dernier point clé :
la discussion reste contextualisée.
L’IA conserve :
- l’historique des échanges,
- les documents déjà consultés,
- le sujet en cours.
On ne fonctionne plus en requêtes isolées, mais en conversation de travail continue.
Conclusion
Utiliser WordPress comme serveur MCP pour la recherche documentaire interne n’est pas un détournement de l’outil, mais une évolution logique de son rôle. WordPress fournit déjà un socle de données structuré, extensible et maîtrisé ; le MCP lui ajoute une couche d’actions explicites, contrôlées et exploitables par une IA.
Cette approche permet de répondre à un besoin très concret : rendre accessible un patrimoine documentaire existant, sans exporter les données, sans dépendre d’infrastructures vectorielles coûteuses et sans exposer inutilement le système. Le contrôle reste côté serveur, les règles sont codées, et l’IA agit uniquement dans le périmètre qui lui est autorisé.
Dans un contexte PME ou intranet technique, cette architecture offre un compromis intéressant entre simplicité, sécurité et efficacité.
Elle ne prétend pas remplacer toutes les solutions vectorielles, mais propose une alternative pragmatique, testable et évolutive, à partir d’outils déjà connus et largement adoptés.
La suite immédiate consiste à observer cette architecture en fonctionnement.
La partie 2 B est consacrée à la mise en œuvre concrète de la recherche documentaire via MCP, à partir d’un WordPress réel et de contenus existants.
Un projet de base documentaire interne ?
WordPress peut devenir bien plus qu’un CMS public : serveur MCP, outils exposés à une IA, contrôle fin des accès et architecture maîtrisée.
Si vous vous posez la question pour votre organisation, on peut en parler simplement.