

Dans les deux premiers épisodes, on a posé le contexte : un site doit devenir plus explicite, et les IA peuvent chercher leurs sources en croisant plusieurs signaux.
Il reste une question centrale : comment décrire proprement ce qu’une page contient ?
C’est là qu’intervient Schema.org. On peut le voir comme une grammaire commune pour les machines. Elle ne remplace pas le contenu visible. Elle ajoute une façon plus structurée de dire ce qu’une page représente, qui parle, qui publie, où la page se situe dans le site, et comment les éléments importants sont reliés.
Pour éviter de se perdre dans la norme, on va partir d’un cas concret : une page d’article.
À garder en tête
Les données structurées ne sont pas une recette magique. Elles ne garantissent ni position, ni Rich Result, ni citation par une IA.
Dans cette série, elles sont traitées comme une couche de clarification : elles aident à déclarer et relier des preuves qui doivent déjà exister dans le contenu visible, les avis, les profils, les produits, la fiche locale et les sources externes.
1. Une page web contient plus que ce que le visiteur voit
Un visiteur arrive sur une page d’article. Il voit un titre, une introduction, des sections, des images, peut-être un auteur, une date, un fil d’Ariane, des liens internes et une conclusion.
Pour lui, tout cela forme une page lisible. Pour une machine, cette même page contient plusieurs informations à identifier : quel est le contenu principal, qui l’a écrit, qui le publie, à quel site il appartient, quelle image le représente, où il se situe dans l’arborescence et quels sujets il aborde.
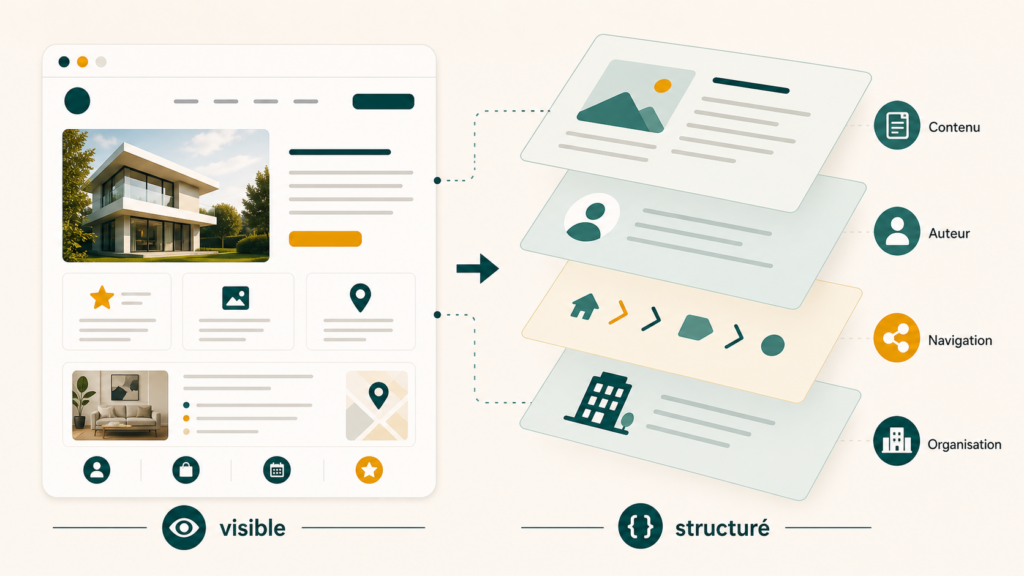
Une partie de ces informations peut être comprise à partir du HTML visible. Mais le HTML ne suffit pas toujours à lever l’ambiguïté. Schema.org ajoute une couche déclarative : il aide à nommer les éléments importants au lieu de laisser le moteur ou l’IA tout reconstruire seul.
2. Schema.org sert à nommer les éléments importants d’une page
Schema.org est un vocabulaire partagé. Il permet de décrire des éléments du monde réel ou du web avec des mots que les machines peuvent reconnaître.
Sur notre page d’article, on peut nommer la page elle-même, le contenu éditorial principal, l’auteur, l’organisation qui publie, le site dans son ensemble et le chemin de navigation. À ce stade, il n’est pas nécessaire de retenir toute la norme.
Il faut surtout comprendre l’idée : Schema.org donne des noms communs à des choses que les sites décrivent souvent chacun à leur manière. Un thème WordPress peut appeler un auteur post-author. Un autre peut utiliser entry-meta. Schema.org ajoute une couche plus stable au-dessus de ces variations.
3. Le type dit ce que c’est, la propriété dit ce qu’on sait
Pour lire un balisage Schema.org, il faut comprendre trois notions : le type, la propriété et la valeur.

Exemple simplifié : Article indique la nature du contenu, headline indique son titre, datePublished indique sa date de publication, et les valeurs sont le titre et la date réelle.
{
"@type": "Article",
"headline": "Schema.org : comprendre la norme des données structurées",
"datePublished": "2026-05-11"
}Cette mécanique est plus importante à comprendre que la liste des centaines de types disponibles. On nomme la chose, puis on déclare ce que l’on sait d’elle.
4. Une page peut être décrite par plusieurs couches reliées
Une page d’article n’est pas un seul bloc. Elle peut être décrite par plusieurs couches : le site, la page, le contenu principal, les personnes et organisations, puis la navigation.
L’intérêt de Schema.org n’est pas d’empiler ces couches comme une décoration. L’intérêt est de dire comment elles se répondent : l’article est publié sur cette page, cette page appartient à ce site, cet article est écrit par cet auteur, cette organisation publie le site, et le fil d’Ariane indique la place de la page dans l’architecture.
On ne décrit donc pas seulement une page. On décrit un petit graphe d’informations.
5. JSON-LD permet d’ajouter cette carte sans modifier le design
Schema.org est le vocabulaire. Il faut ensuite choisir un format pour l’intégrer dans la page. Les principaux formats sont JSON-LD, Microdata et RDFa.
Google indique prendre en charge ces trois formats pour les données structurées, mais recommande JSON-LD quand c’est possible. JSON-LD est souvent le plus pratique dans WordPress parce qu’il permet de placer les données structurées dans un bloc séparé du HTML visible.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Schema.org : comprendre la norme des données structurées",
"author": {
"@type": "Person",
"name": "Nom de l’auteur"
}
}
</script>Le visiteur ne voit pas ce bloc. Il voit la page, le titre, le texte et le design. La machine, elle, peut lire une carte plus structurée du contenu.
6. @graph permet de rassembler plusieurs éléments dans une même carte
Quand une page contient plusieurs entités reliées, on peut utiliser @graph. Il permet de regrouper plusieurs objets Schema.org dans un même bloc JSON-LD.
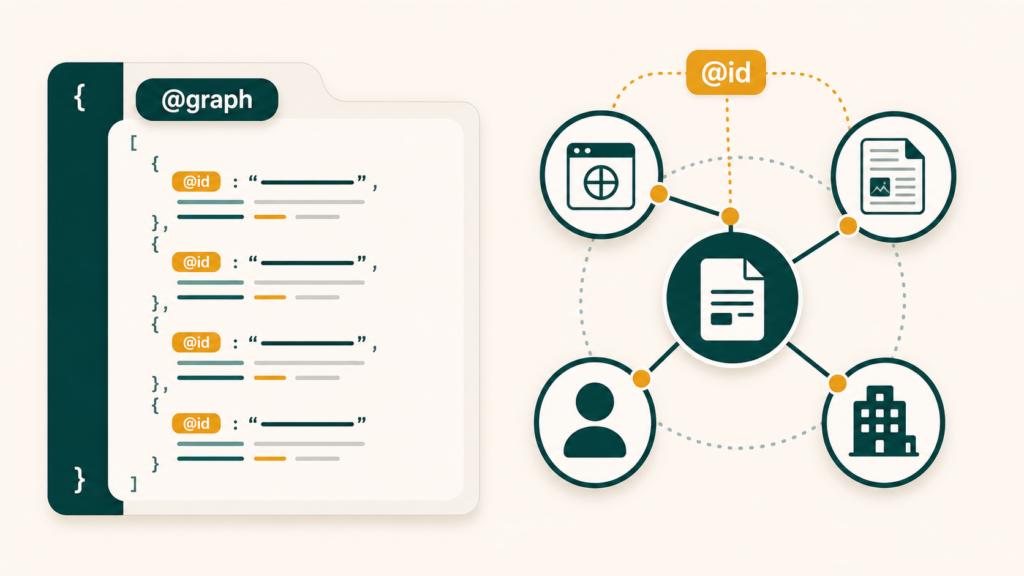
@graph aide à penser en relations, pas seulement en fiche isolée.{
"@context": "https://schema.org",
"@graph": [
{
"@type": "WebSite",
"@id": "https://example.com/#website",
"name": "Nom du site"
},
{
"@type": "Organization",
"@id": "https://example.com/#organization",
"name": "Nom de l’entreprise"
},
{
"@type": "Article",
"headline": "Titre de l’article",
"publisher": {
"@id": "https://example.com/#organization"
}
}
]
}Ce code est volontairement incomplet. Il sert seulement à montrer l’idée : plusieurs éléments peuvent cohabiter dans la même carte, puis se relier entre eux.
7. @id évite de recréer plusieurs fois la même entité
@id sert à donner un identifiant stable à une entité. Par exemple, l’organisation principale du site peut être identifiée ainsi : https://example.com/#organization.
Ensuite, plusieurs éléments peuvent pointer vers cette même organisation. L’intérêt est simple : on évite de recréer des organisations différentes à chaque page. La même entité reste la même entité.
Pour les moteurs et les IA, cette stabilité est précieuse. Elle aide à comprendre que plusieurs pages parlent bien des mêmes personnes, marques, sites ou organisations.
8. Schema.org n’est pas la même chose que les Rich Results Google
Il faut distinguer deux sujets. Schema.org est un vocabulaire très large. Google Rich Results est un ensemble beaucoup plus restreint d’affichages enrichis que Google peut décider d’utiliser dans ses résultats.

Tout ce qui existe dans Schema.org n’ouvre pas droit à un affichage enrichi dans Google. Un balisage peut être valide, utile pour clarifier une entité, ignoré pour les Rich Results, non affiché dans Google, et quand même pertinent pour la compréhension machine.
C’est pour cela que l’épisode suivant sera consacré à Google Rich Results. On y séparera ce que Google reconnaît officiellement pour ses affichages enrichis de ce que Schema.org permet plus largement de décrire.
9. Les données déclarées doivent rester cohérentes avec le contenu visible
Schema.org ne doit pas servir à inventer une réalité parallèle. Les données structurées doivent décrire ce qui existe réellement sur la page ou dans le site.
Il faut éviter de déclarer une FAQ qui n’est pas visible, d’ajouter des avis inexistants, de déclarer un prix faux, d’inventer un auteur ou de déclarer des services qui ne sont pas réellement proposés.
La règle est simple : ce que l’on déclare aux machines doit rester cohérent avec ce que l’on montre aux humains. Cette cohérence est aussi importante pour les IA, qui doivent recouper le contenu visible, la fiche Google, les avis, les profils publics et les données structurées.
10. Comprendre Schema.org aide à décider quoi baliser en priorité
Une fois la logique comprise, on peut l’appliquer à d’autres types de sites. Un site éditorial devra surtout clarifier qui publie, qui écrit, où se trouve la page dans l’arborescence et quel contenu fait autorité.
Une entreprise locale devra rendre lisibles son identité, sa zone réelle, ses services, ses horaires, ses preuves et ses profils publics. Une boutique WooCommerce devra permettre aux machines de comparer les produits avec des informations fiables : prix, disponibilité, marque, avis, catégorie, variantes ou relation avec les pages de collection.
Schema.org devient utile quand il sert une lecture claire du site. Pas quand il devient une collection de balises décoratives.
11. Un cas réel demande une cartographie avant de produire du JSON-LD
Imaginons une entreprise de services implantée depuis 20 ans. Son siège est à Caen, dans le Calvados. Elle possède aussi deux succursales : une à Saint-Lô, dans la Manche, et une à Paris. Chaque succursale compte environ 15 personnes.
L’entreprise est bien implantée localement. Sa clientèle revient, elle possède des profils sociaux, une page LinkedIn, une page Facebook, des fiches Google Business Profile et des avis pour chaque établissement.
Son site contient une page d’accueil, une page à propos, une page services qui liste les offres, une page dédiée par service, un blog avec une liste d’articles, et une page contact avec choix de succursale.
Dans ce cas, la question n’est pas de générer du JSON-LD trop vite. La première étape consiste à cartographier les entités : organisation principale, succursales, pages de services, pages d’établissements, profils publics, avis, zones desservies et liens entre les contenus.
Ce type de cas demande des choix. Ce sera le rôle de la saison 2 : passer de la compréhension de la norme à la mise en place concrète dans WordPress.
12. Les erreurs fréquentes viennent souvent d’un balisage automatique trop générique
Les plugins SEO généralistes rendent service. Ils ajoutent souvent une base Schema.org correcte : identité du site, pages, contenus éditoriaux, parfois fil d’Ariane, auteurs ou produits selon les extensions.
Mais cette base peut rester générique. Elle ne connaît pas toujours les vrais champs métiers, les vraies zones d’intervention, les types de services précis, les relations entre contenus, les profils publics des auteurs ou les subtilités d’un catalogue WooCommerce.
Un balisage automatique peut donc être valide sans être très expressif. Avant de passer à la mise en place WordPress, il reste une étape importante : distinguer la norme Schema.org de ce que Google utilise réellement pour ses Rich Results.
Ce qu’il faut retenir
Schema.org est une grammaire commune. Elle permet de nommer les éléments importants d’un site et de clarifier leurs relations dans un format lisible par les machines.
JSON-LD est souvent le format le plus pratique pour intégrer ces données dans WordPress. Mais la priorité n’est pas de tout baliser. La priorité est de déclarer correctement les entités importantes, avec des informations vraies, cohérentes et utiles.
Dans l’épisode suivant, on verra ce que Google reconnaît officiellement comme Rich Results, et pourquoi il faut distinguer la norme Schema.org des affichages enrichis dans les résultats de recherche.
Besoin de rendre votre site plus compréhensible ?
Les données structurées ne remplacent pas une stratégie SEO. Elles renforcent la clarté du site, de ses contenus, de ses auteurs, de ses services et de ses entités.
Cet article fait partie de la série Données structurées, Rich Results et IA.

La série est organisée en parties : comprendre, appliquer, puis développer les cas stratégiques.
Cette série est découpée en 3 grandes parties. Le mot « saison » sert ici a organiser la progression éditoriale, pas a annoncer une publication l’année prochaine 😉 .
- Saison 1 : comprendre les bases ;
- Saison 2 : appliquer dans WordPress ;
- Saison 3 : développer les cas stratégiques. SEO local, auteurs et WooCommerce.
- S3E1 – GEO local : Google Business Profile, avis et assistants de decision
- S3E2 – Auteurs, E-E-A-T et profils publics : rendre l’expertise identifiable
- S3E3 – WooCommerce, Product, Offer et comparatifs IA : rendre les produits vérifiables
- S3E4 – Réassurance distribuée : quand la confiance se construit sur tout le web
- Final : du SEO classique au GEO, comprendre la lecture en réseau


