

Le titre de cet épisode peut prêter à confusion.
“Démo plugin” pourrait laisser croire qu’il s’agit de présenter une solution prête à installer, capable de gérer toutes les données structurées d’un site WordPress.
Ce n’est pas le cas.
Il s’agit d’un plugin de test, pensé comme un outil de développement et de validation. Son rôle est d’expérimenter une méthode : reprendre la main sur les entités, vérifier les champs, construire un graphe JSON-LD plus cohérent et tester ce qui sort réellement dans le code.
Les deux premiers épisodes de la saison 2 posaient deux idées.
D’abord, WordPress, WooCommerce et les plugins SEO génèrent déjà une partie des données structurées. Ensuite, il ne faut pas tout baliser partout : il faut choisir les entités qui correspondent vraiment au site.
Cet épisode passe côté développement.
Je vais donc parler d’un plugin de test, développé dans le lab, qui sert à piloter des données structurées avancées dans WordPress.
Ce n’est pas un plugin miracle. Ce n’est pas un outil qui pourrait convenir tel quel à tous les sites, toutes les organisations, toutes les taxonomies, tous les CPT et toutes les logiques métier.
C’est justement le point important.
Un bon plugin de données structurées doit s’adapter au site. Si quelqu’un vend un plugin générique censé comprendre parfaitement toutes les organisations, toutes les listes, tous les champs ACF, tous les produits, tous les auteurs et tous les types de contenus, il y a de fortes chances que cela devienne une usine à gaz.
À garder en tête
Les données structurées ne sont pas une recette magique. Elles ne garantissent ni position, ni Rich Result, ni citation par une IA.
Dans cette série, elles sont traitées comme une couche de clarification : elles aident à déclarer et relier des preuves qui doivent déjà exister dans le contenu visible, les avis, les profils, les produits, la fiche locale et les sources externes.
1. Le plugin est d’abord un outil de test et de validation côté développement
Le premier rôle du plugin n’est pas de “faire du SEO automatiquement”.
Son rôle est plus concret : permettre de générer un schéma propre, contrôlable, testable et adapté aux données réelles du site.
Dans une logique de développement, c’est précieux.
On peut vérifier ce qui sort dans le JSON-LD, tester les types déclarés, contrôler les relations entre les entités, repérer les doublons, comparer avec les sorties d’un plugin SEO, puis valider avec les outils Google et Schema.org.
Le plugin devient donc une sorte de banc de test.

Il permet de répondre à des questions simples :
- quelle entité principale est déclarée sur cette page ?
- l’auteur est-il bien relié à l’article ?
- l’organisation est-elle déclarée une seule fois ?
- le fil d’Ariane correspond-il au silo réel ?
- la FAQ visible est-elle bien reprise ?
- les champs ACF sont-ils correctement utilisés ?
- les CPT génèrent-ils un schéma cohérent ?
- les données déclarées sont-elles visibles ou justifiables dans le contenu ?
Le but est de valider le schéma au niveau du développement, avant de le considérer comme une couche SEO exploitable.
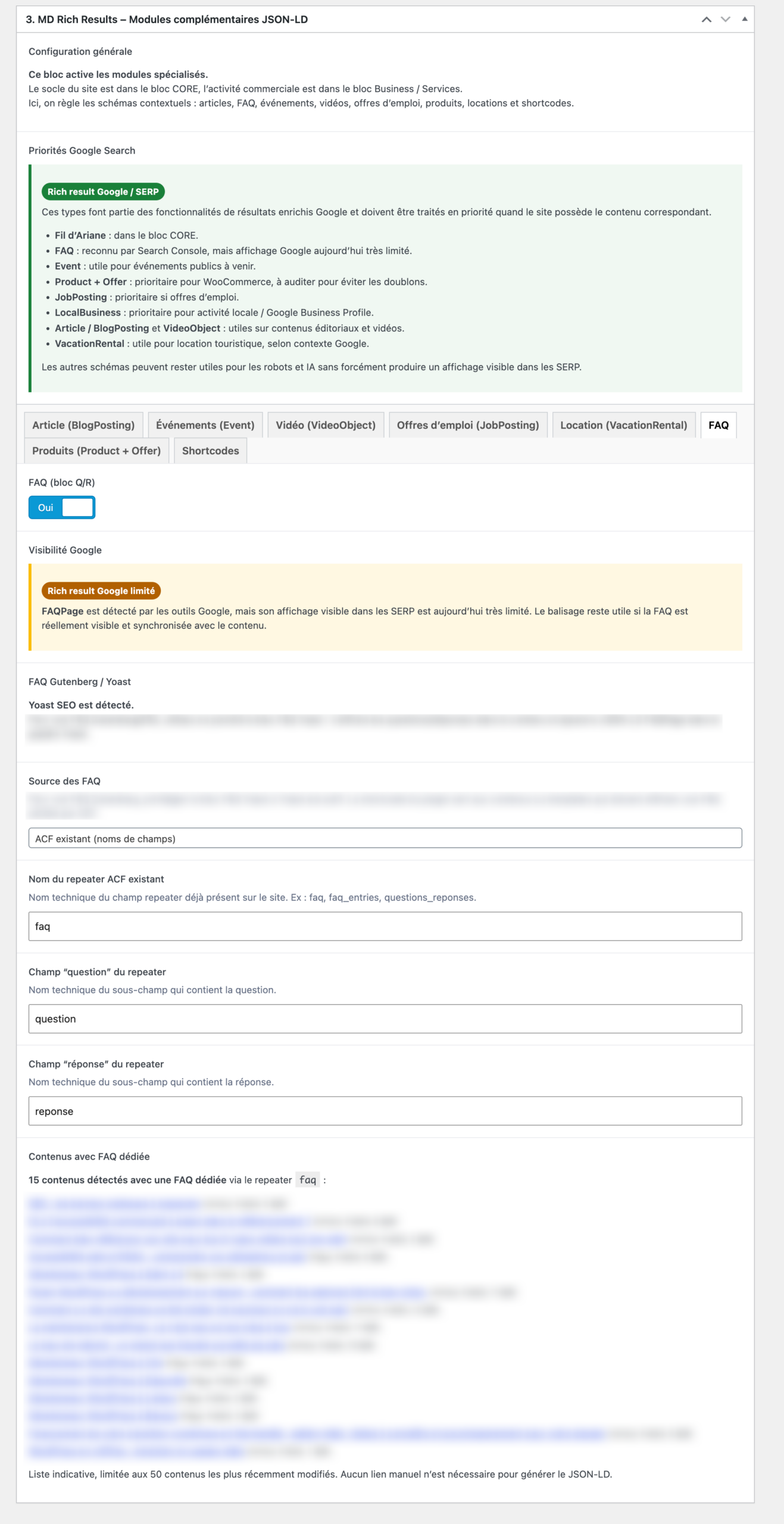
2. Premier constat du test : les entités sont séparées au départ
Le premier enseignement du plugin est assez simple : au départ, les entités sont souvent séparées.
Sur un site WordPress classique, les données structurées peuvent venir de plusieurs endroits.
Le thème peut gérer une partie du fil d’Ariane. Un plugin SEO peut déclarer le site, la page, l’article et l’organisation. WooCommerce peut ajouter des données produit. Un bloc FAQ peut injecter un schéma séparé. Un autre plugin peut ajouter un événement ou une vidéo.
Chaque bloc peut être valide isolément.
Mais l’ensemble peut devenir difficile à lire.
Ce que le plugin m’a montré, c’est que le vrai sujet n’est pas seulement de “produire du Schema.org”.
Le vrai sujet est de comprendre quelles entités existent déjà, d’où elles viennent, puis de décider comment les réunir ou les relier dans un graphe plus cohérent.
Le plugin custom permet alors de reprendre la main sur ces entités séparées.
L’idée n’est pas d’empiler encore un script JSON-LD de plus.
L’idée est de construire une sortie plus lisible pour les robots :
- une organisation stable ;
- une page clairement identifiée ;
- un contenu principal ;
- un auteur relié à son profil ;
- une image principale ;
- un fil d’Ariane cohérent ;
- des entités secondaires seulement quand elles existent vraiment ;
- des relations explicites entre les objets.
On retrouve ici la logique de @graph : plusieurs entités existent, mais elles ne flottent pas séparément. Elles sont reliées.
3. Les pages statiques doivent souvent être renseignées avec des champs explicites
Les pages statiques posent une difficulté particulière.
Une page “À propos”, “Services”, “Contact” ou “Nos agences” peut être construite dans Gutenberg avec des blocs très variés.

Scanner automatiquement le contenu Gutenberg pour en extraire des données fiables est possible dans certains cas, mais cela reste fragile.
Le HTML peut changer. Les blocs peuvent être imbriqués. Certains contenus peuvent être masqués. Les textes peuvent être déplacés. Les classes changent selon le thème ou le builder.
Pour des données structurées fiables, il vaut mieux éviter de deviner.
Sur les pages statiques importantes, des champs ACF peuvent être plus propres :
- type de page ;
- service principal ;
- zone desservie ;
- établissement concerné ;
- personne référente ;
- téléphone ;
- adresse ;
- liens publics ;
- questions fréquentes ;
- image principale ;
- relation avec une autre page.
Gutenberg reste là pour le contenu visible et éditorial.
Les champs ACF servent à déclarer les données que le plugin doit reprendre sans ambiguïté.
Ce n’est pas toujours nécessaire sur toutes les pages. Mais pour les pages structurantes, c’est souvent plus robuste.
Là encore, le plugin ne peut pas décider seul. Il peut proposer une méthode, mais le choix des champs utiles dépend de la page, de son rôle dans le site et des informations vraiment visibles.
4. Les articles, événements et références sont parfois automatisables
Tous les contenus ne demandent pas le même niveau de saisie manuelle.
Un article de blog est souvent assez automatisable.
WordPress connaît son titre, son auteur, sa date de publication, sa date de modification, son image mise en avant, son URL, sa catégorie et son extrait. Le plugin peut donc produire une base cohérente sans trop demander à l’administrateur.
Mais même sur un article, il faut rester prudent. L’auteur peut être important sur un site éditorial ou expert, mais beaucoup moins sur un contenu très institutionnel, une note courte, une archive technique ou un article repris d’une autre logique éditoriale. Le plugin peut utiliser l’auteur, mais il ne doit pas supposer que le même traitement convient partout.
Un CPT “référence” ou “réalisation” peut aussi être assez automatisable si ses champs sont bien définis : client, secteur, lieu, image, date, résumé, prestation, lien vers le service concerné.
Un CPT “event” peut être plus délicat.
Le type Event possède de nombreux champs possibles : nom, description, date de début, date de fin, lieu, organisateur, statut, mode de présence, prix, offre, URL d’inscription, image, fuseau horaire, disponibilité, etc.
Il faudra donc prévoir une transition.
On peut commencer par un schéma événementiel minimal, puis enrichir progressivement les champs selon les besoins réels du client.
Le piège serait de vouloir tout remplir dès le départ. Le meilleur chemin est souvent : minimum propre, puis enrichissement progressif.
Même quand une partie du balisage peut être automatisée, la décision reste donc au cas par cas.
5. La FAQ reste un bon exemple de schéma simple, mais plus un levier Rich Result Google
Mise à jour importante
Depuis l’annonce de Google du 8 août 2023, les résultats enrichis FAQ ont été fortement réduits dans la recherche Google. La documentation actuelle indique désormais qu’ils n’apparaissent plus dans Google Search depuis le 7 mai 2026.
Le balisage FAQPage reste présent dans Schema.org, mais il ne doit plus être pensé comme un levier de Rich Result Google. Il peut encore avoir du sens si la FAQ est visible sur la page, utile pour l’utilisateur, et cohérente avec le contenu principal.
La FAQ est plus simple à gérer, mais elle montre bien la différence entre un bloc isolé et une donnée intégrée au graphe.
Il existe déjà des plugins qui mettent à disposition un bloc FAQ Gutenberg, avec génération automatique de données structurées.

C’est pratique.
Mais il y a une limite : la FAQ peut être générée comme un schéma à part, sans être réellement intégrée au graphe principal de la page.
Elle existe, mais elle n’est pas forcément reliée proprement au post ou à la page en cours, à son auteur, à son organisation, à son fil d’Ariane ou à son contenu principal.
La solution que je préfère tester est plus contrôlée : des champs ACF + un shortcode d’affichage.
Avec ACF, on peut prévoir un répéteur avec deux champs :
- question ;
- réponse.
Le plugin peut ensuite générer un schéma FAQPage conforme à Schema.org à partir de ces champs, seulement quand la FAQ est réellement affichée sur la page. L’objectif n’est plus d’obtenir un résultat enrichi FAQ dans Google, mais de garder une donnée claire, cohérente et exploitable par les systèmes qui lisent le contenu structuré.
Le shortcode sert à afficher cette même FAQ dans le contenu visible.
On peut aussi imaginer une solution hybride : insérer un bloc FAQ côté Gutenberg, mais ajouter les champs ACF nécessaires pour que le plugin produise un JSON-LD propre et relié au graphe.
Cette logique est plus fiable que de scanner automatiquement du contenu Gutenberg pour essayer de deviner quelles lignes sont des questions et quelles lignes sont des réponses.
Elle permet aussi de garder une cohérence simple :
- la question est saisie ;
- la réponse est saisie ;
- le shortcode ou le bloc visible affiche la FAQ ;
- le JSON-LD reprend les mêmes données ;
- la FAQ peut être reliée à la page en cours dans le graphe.
La règle reste la même : on ne déclare pas une FAQ invisible.
Le schéma doit correspondre au contenu visible.
La FAQ montre donc bien les trois chemins possibles : utiliser un bloc FAQ existant, piloter la FAQ avec des champs ACF et un affichage contrôlé, ou combiner Gutenberg et des champs structurés. Le bon choix dépend du site, de la manière dont les contenus sont saisis, et du niveau de contrôle attendu sur le graphe JSON-LD.
6. Le profil auteur devient une fonctionnalité visible, pas seulement une donnée cachée
Le plugin peut aussi servir à travailler les profils auteurs, mais il ne faut pas développer tout le sujet ici.
Dans cette démo, l’idée technique est simple : ajouter des champs au profil utilisateur WordPress, puis utiliser un shortcode pour afficher le même bloc auteur sous les articles et sur la page auteur.
Cela évite de saisir une bio à plusieurs endroits et de créer des écarts entre le contenu visible et les données structurées.
Le plugin peut ainsi préparer une base propre pour Person ou ProfilePage :
- photo ;
- nom ;
- fonction ;
- courte bio ;
- expertise ;
- profils publics utiles ;
- lien vers la page auteur.
Ce bloc visible aide le lecteur.
Le balisage aide les machines.
Les deux doivent raconter la même chose.
Le sujet complet sera traité dans la saison 3 : page auteur comme page de preuve, E-E-A-T, profils publics, contributions externes, liens vers LinkedIn, YouTube, conférences, interviews et autres signaux permettant aux IA de reconnaître une personne fiable.
7. Le type de business ne se choisit pas à la légère
Schema.org propose beaucoup de types liés aux organisations et aux entreprises locales.
La liste est longue.
Il peut être tentant de choisir un type très précis pour “faire mieux”.
Mais ce choix doit rester cohérent avec l’activité réelle du site.
Une entreprise peut être déclarée comme Organization, LocalBusiness, ou avec un sous-type plus précis si cela correspond vraiment. Mais il ne faut pas forcer un type simplement parce qu’il semble plus optimisé.
Le plugin peut proposer une liste de types. Mais là encore, la configuration doit rester accompagnée.
Le bon type dépend :
- de l’activité ;
- du modèle économique ;
- de l’existence ou non de lieux physiques ;
- des fiches Google Business Profile ;
- des services réellement proposés ;
- des pages visibles sur le site ;
- des informations disponibles.
8. La leçon du test : une couche adaptée vaut mieux qu’un plugin universel
Dans cet article, un plugin custom désigne une couche technique conçue pour un site précis.
Ce plugin custom lit les contenus du site, ses champs, ses taxonomies, ses auteurs, ses pages importantes et ses règles métier. Il utilise ensuite ces informations pour produire un graphe JSON-LD cohérent avec le contenu visible.
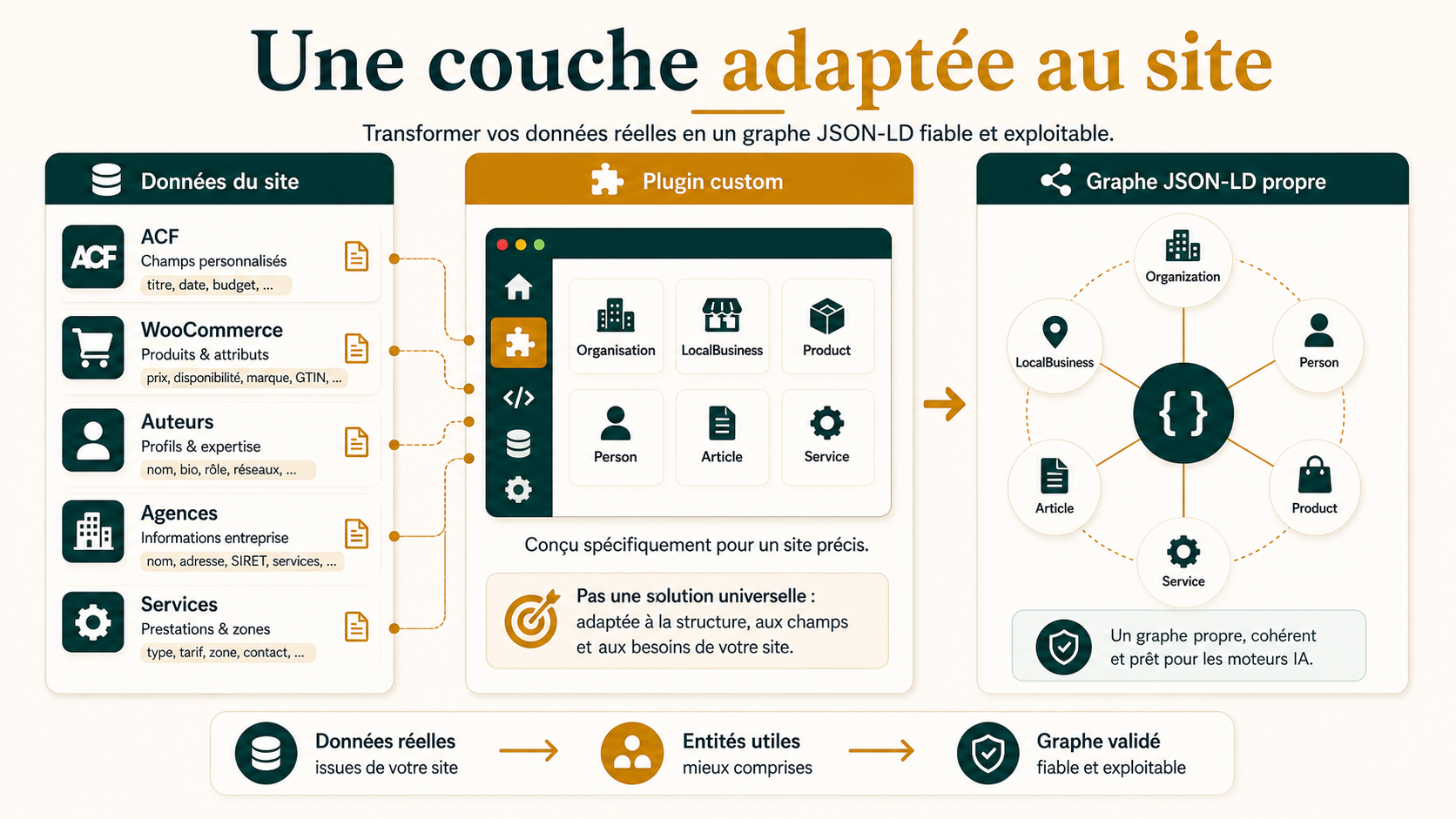
Le test montre surtout une chose : un plugin custom est utile quand il part des données réelles du site et déclare seulement les entités utiles.
Un plugin générique peut rendre service. Il peut poser une base, corriger des champs, déclarer des types simples, ajouter un fil d’Ariane ou améliorer l’éligibilité à certains Rich Results.
Mais un plugin générique atteint vite sa limite dès que les données du site suivent une organisation spécifique. Il ne peut pas toujours savoir quelles pages comptent vraiment, quels champs sont fiables, quels auteurs doivent être mis en avant, ni quelles relations doivent être déclarées entre les entités.
Contrairement à l’idée d’une extension capable de tout couvrir partout, un plugin custom assume donc un périmètre précis.
Un site peut avoir un CPT “références”. Un autre un CPT “réalisations”. Un autre un CPT “formations”. Un autre un catalogue WooCommerce avec producteurs. Un autre des agences locales. Un autre des pages de services qui dépendent de zones géographiques.
Ce ne sont pas seulement des différences de configuration. Ce sont des différences de structure.
Un plugin custom peut donc rester simple. Il part des données disponibles, identifie les pages et contenus stratégiques, définit les entités nécessaires, génère un graphe JSON-LD propre, puis valide ce qui sort réellement dans le code.
Ensuite seulement, on enrichit si cela apporte une vraie clarté.
Un plugin custom utile sait exactement ce qu’il doit déclarer.
Ce qu’il faut retenir sur le plugin de démonstration
Ce test valide surtout une idée : pour produire des données structurées de qualité, le plugin doit s’adapter aux données réelles du site.
Les plugins SEO largement diffusés posent une base utile, mais ils restent souvent standardisés. Ils peuvent déclarer des entités correctes, mais sans toujours construire un graphe unique, cohérent et vraiment adapté à l’organisation du site.
Un plugin de données structurées “à tout faire” rencontre la même limite. Chaque site possède ses contenus, ses champs, ses auteurs, ses produits, ses pages importantes, ses taxonomies et ses règles métier. Une solution identique pour tous les sites finit donc vite par être incomplète, trop lourde ou mal ajustée.
La solution la plus solide est un plugin custom conçu pour les données du site. Il part de ce qui existe réellement, structure les entités utiles et produit un graphe JSON-LD clair, cohérent avec le contenu visible.
Un plugin ne suffit pas si la structure SEO reste floue
Les données structurées peuvent clarifier un site, mais elles s’appuient sur une base plus large : contenus utiles, pages bien organisées, maillage interne lisible et entités cohérentes.
Cet article fait partie de la série Données structurées, Rich Results et IA.

La série est organisée en parties : comprendre, appliquer, puis développer les cas stratégiques.
Cette série est decoupée en 3 grandes parties. Le mot « saison » sert ici a organiser la progression editoriale, pas a annoncer une publication l’année prochaine 😉 .
L’idee :
- Saison 1 : comprendre les bases ;
- Saison 2 : appliquer dans WordPress ;
- Saison 3 : développer les cas stratégiques. SEO local, auteurs et WooCommerce.
- S3E1 – GEO local : Google Business Profile, avis et assistants de decision
- S3E2 – Auteurs, E-E-A-T et profils publics : rendre l’expertise identifiable
- S3E3 – WooCommerce, Product, Offer et comparatifs IA : rendre les produits vérifiables
- S3E4 – Réassurance distribuée : quand la confiance se construit sur tout le web
- Final : du SEO classique au GEO, comprendre la lecture en réseau
Les épisodes peuvent etre publiés progressivement, avec d’autres articles intercalés entre deux épisodes.


